[hmpdacc] Human Microbiome Project의 파일 다운받기
Human Microbiome Project는 NIH주관으로 2007년에 시작한 컨소시엄이다. 인간의 각 부위별 미생물 프로파일 식별을 목표로 수행되었으며, 2016년에 마무리되었다.
2014 년도부터 두 번째 연구인 Integrative Human Microbiome Project (iHMP)로 질병과 미생물 간의 이해를 증진시키기 위한 추가 연구가 진행되고 있다.
- 홈페이지: https://hmpdacc.org/
NIH Human Microbiome Project - Home
Characterization of microbiome and human host from three cohorts of microbiome-associated conditions, using multiple 'omics technologies. Enter iHMP
hmpdacc.org
위 프로젝트의 데이터는 오픈되어 있으며, 포털(https://portal.hmpdacc.org/)을 통해서 데이터에 접근 가능하다. 데이터를 다운로드하는 방법은 hmp_client(https://github.com/michbur/hmp_client)를 사용하거나, Aspera(https://hmpdacc.org/hmp/resources/download.php)를 사용하는 방법 등이 있다. 그러나 가장 간단한 방법은 포털에 직접 접속하고, 원하는 데이터를 선택한 후, 다운로드하는 방법이다.
다운 방법
1. 포털 접속
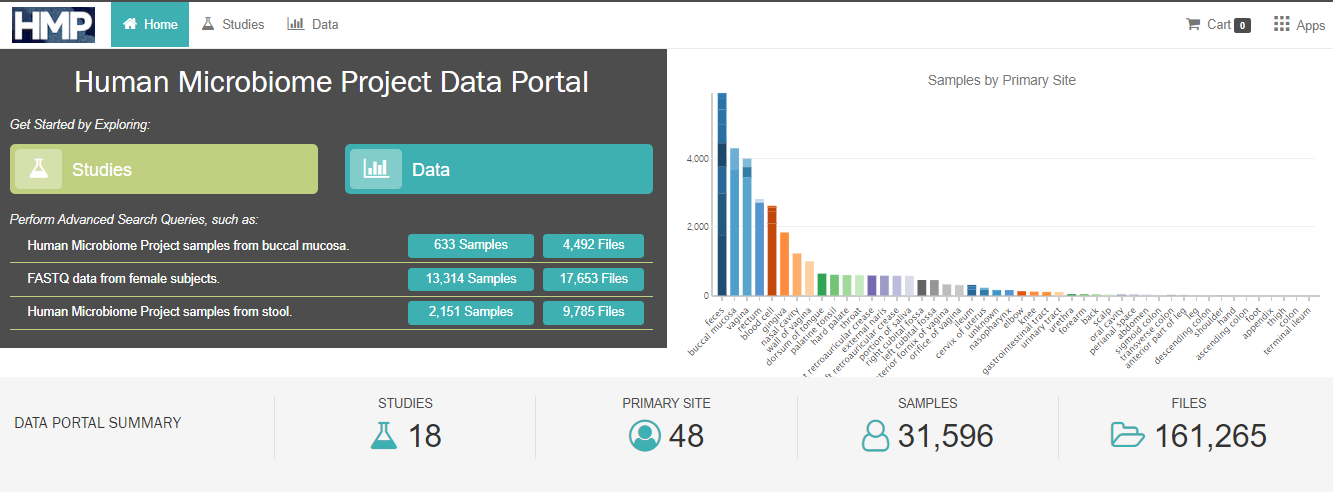
2. 원하는 데이터 선택
- [Data]로 이동 -> 원하는 Project, Body Site, Studies, Gender를 선택할 수 있다.
Studies는 " 16S-SM-P ", Body Sites는 " scalp "를 선택해 보자.
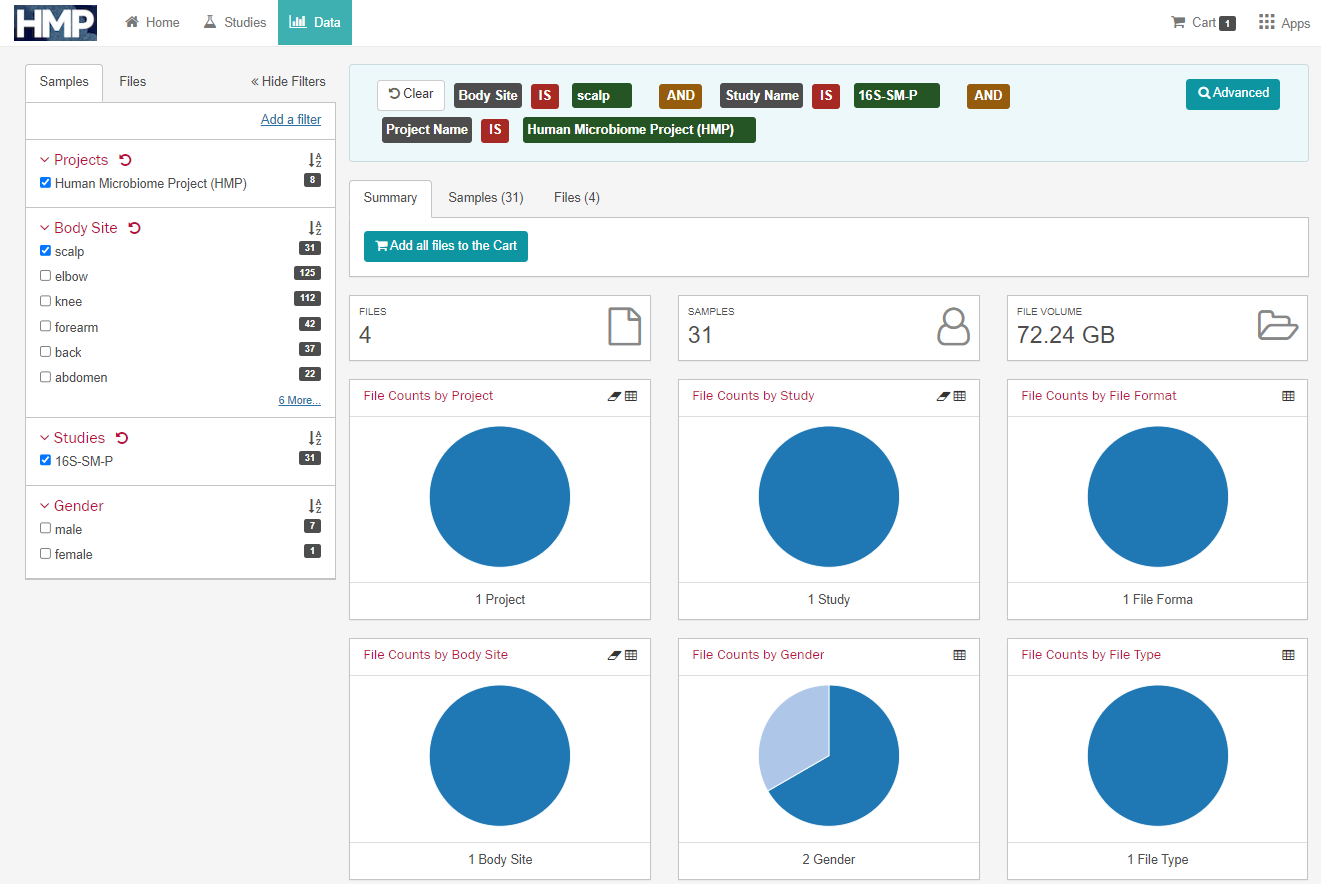
위 샘플에 해당하는 데이터는 31개, 대상자는 8명인 것을 알 수 있다.
샘플은 31개이지만, 이는 4개의 파일에 나누어져 있다.
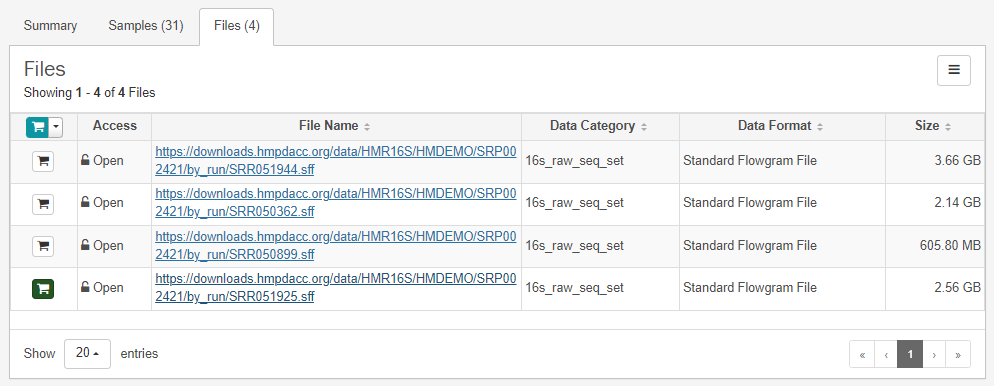
이때 다운로드하고자 하는 파일을 카트에 저장한다.
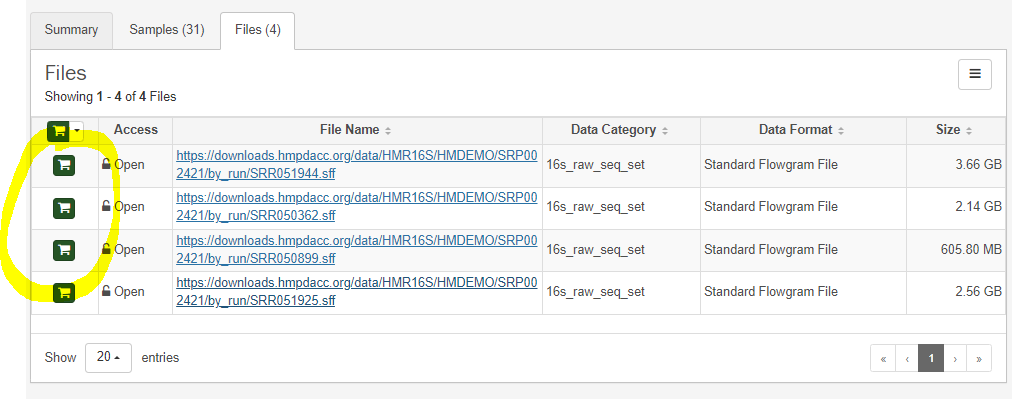
3. 선택한 파일의 정보 다운로드
카트 페이지로 이동하면 아래 화면을 볼 수 있다.
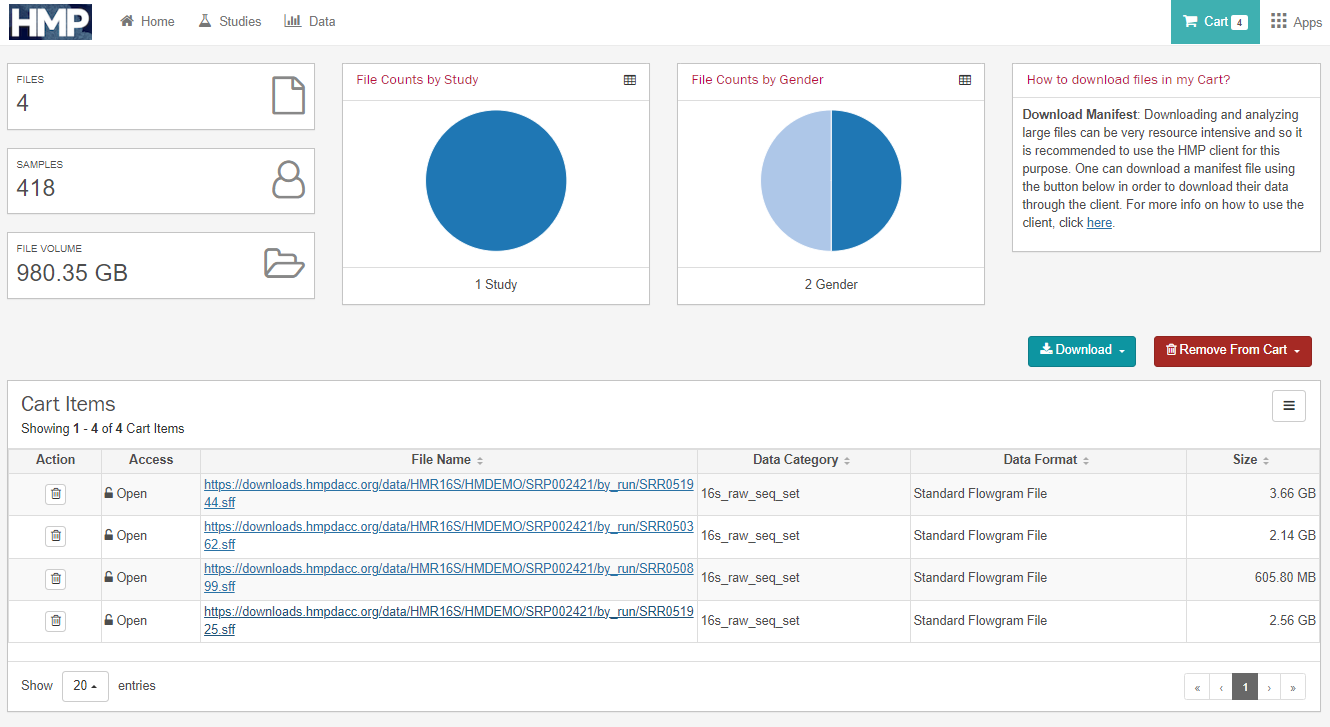
다운로드 버튼에서 샘플의 Manifest와 Metadata를 다운로드할 수 있다.
아쉬운 것은 시퀀싱 런에 따라 저장되어 있기 때문에, 내가 원하는 파일은 31개이지만, 위 파일을 모두 다운로드하면 약 400개의 파일정보를 모두 다운로드하게 된다.
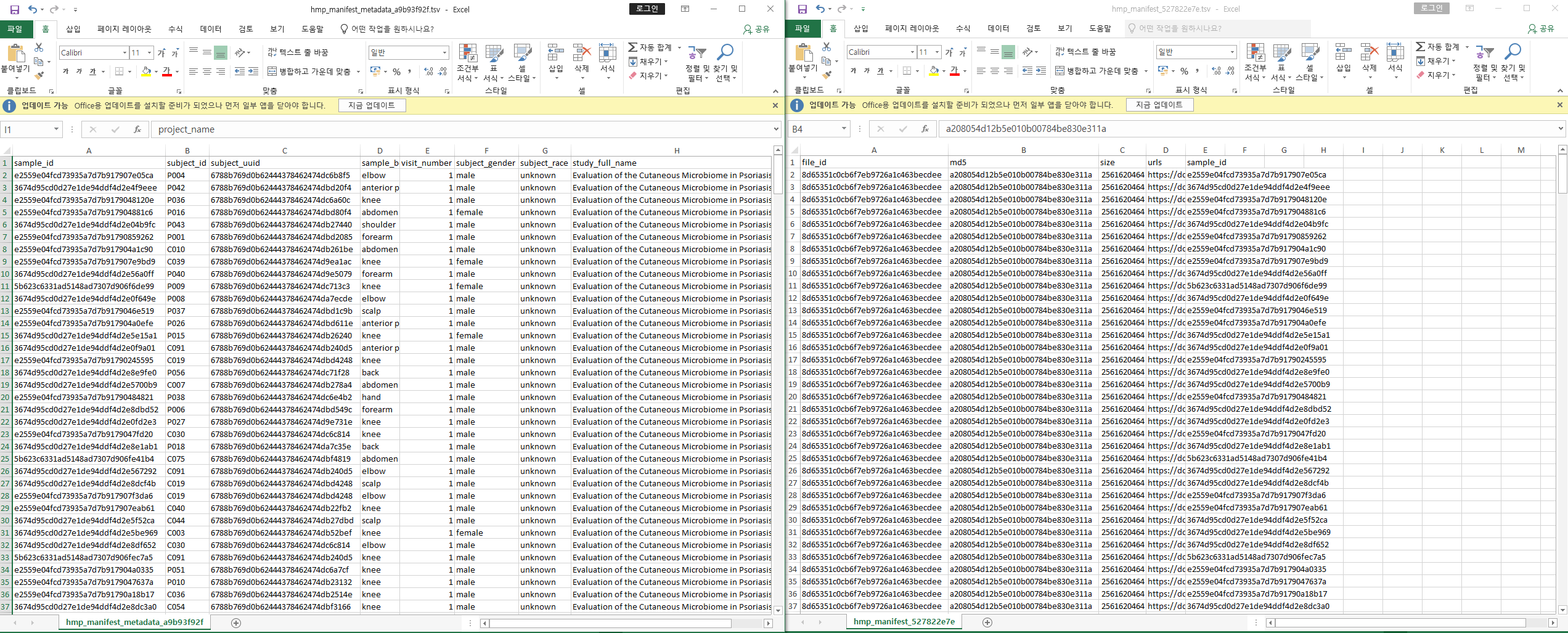
여기서 두 엑셀시트를 sample_id에 따라 합치고, Scalp에 해당하는 데이터만 추린다.
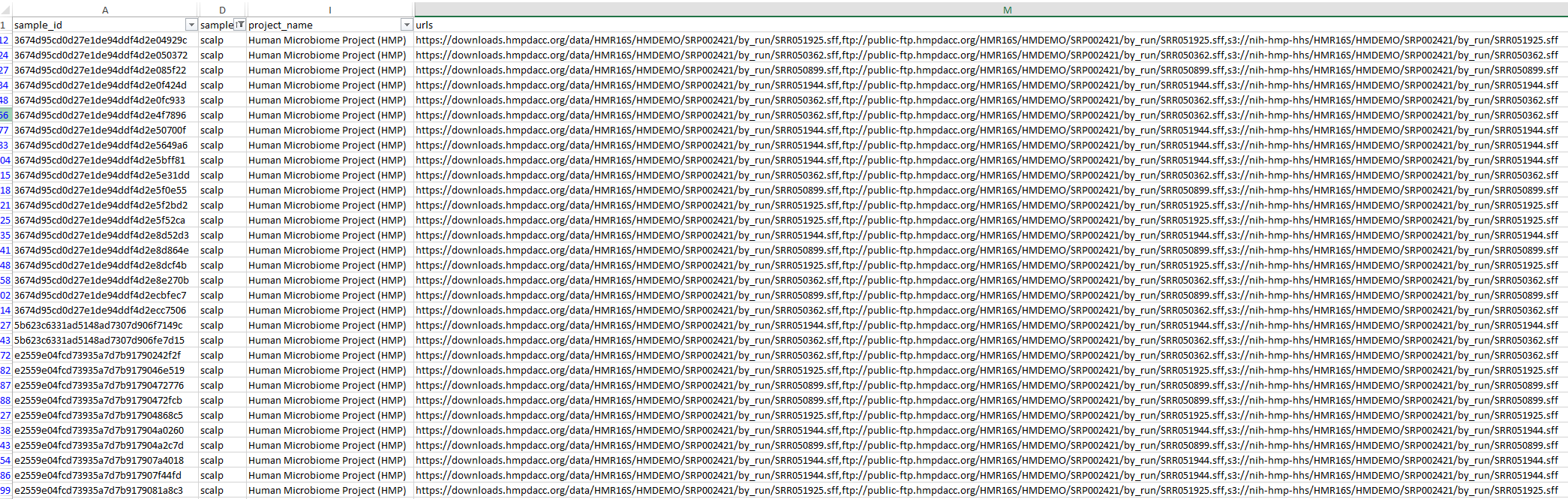
4. 파일 다운로드
엑셀 시트에서 urls부분에 해당하는 주소가 파일을 다운로드할 수 있는 주소이다.
urls열을 [데이터]-[텍스트나누기]-[구분기호]-[쉼표]로 나누어주면, https, ftp, s3를 사용해 각각 다운로드하는 링크를 얻을 수 있다.
링크는 총 4개이며, 리눅스 서버에서 wget이나 ftp를 사용해 손쉽게 다운로드가 가능하다!