
자 이제 실제로 데이터베이스를 만들어 봅시다. 저는 무언가를 배우는 가장 빠른 길이 일상생활에 적용해 보는 것이라고 생각합니다. 두 마리의 새를 잡기 위해서 실제 프로젝트를 수행하면서 데이터 베이스 관리 시스템을 공부하고자 합니다.
⚠ 비전공자의 야매 프로젝트 입니다 ⚠
이전 글
생물학도가 왜 데이터베이스 관리 시스템을 배워야 할까?
작성: 2024.12.15 이번 학기에 데이터관리에 대한 매우 유익한 수업을 듣게 되었습니다. 이에 대한 감상을 공유하고자 합니다.과목의 이름은 "생의학 데이터분석"으로, 생물 및 의학분야의 데이
bio-kcs.tistory.com
1. 연구실 데이터베이스 구축의 필요성
저희 연구실을 예시로 들자면, 임상환자를 보는 외래와 연구실 데이터로 크게 나눌 수 있습니다.
병원 내 연구실의 가장 큰 장점은 환자 데이터를 얻을 수 있다는 것인데요. 하지만 데이터 양이 방대해 관리의 어려움을 겪고 있었습니다.
2. 데이터베이스 설계 단계
먼저 우리가 어떤 데이터를 모아야 하는지 개념적인 설계를 하고, 추후 확장성을 고려하여 초기 모델을 구현하는 식으로 수행됩니다.
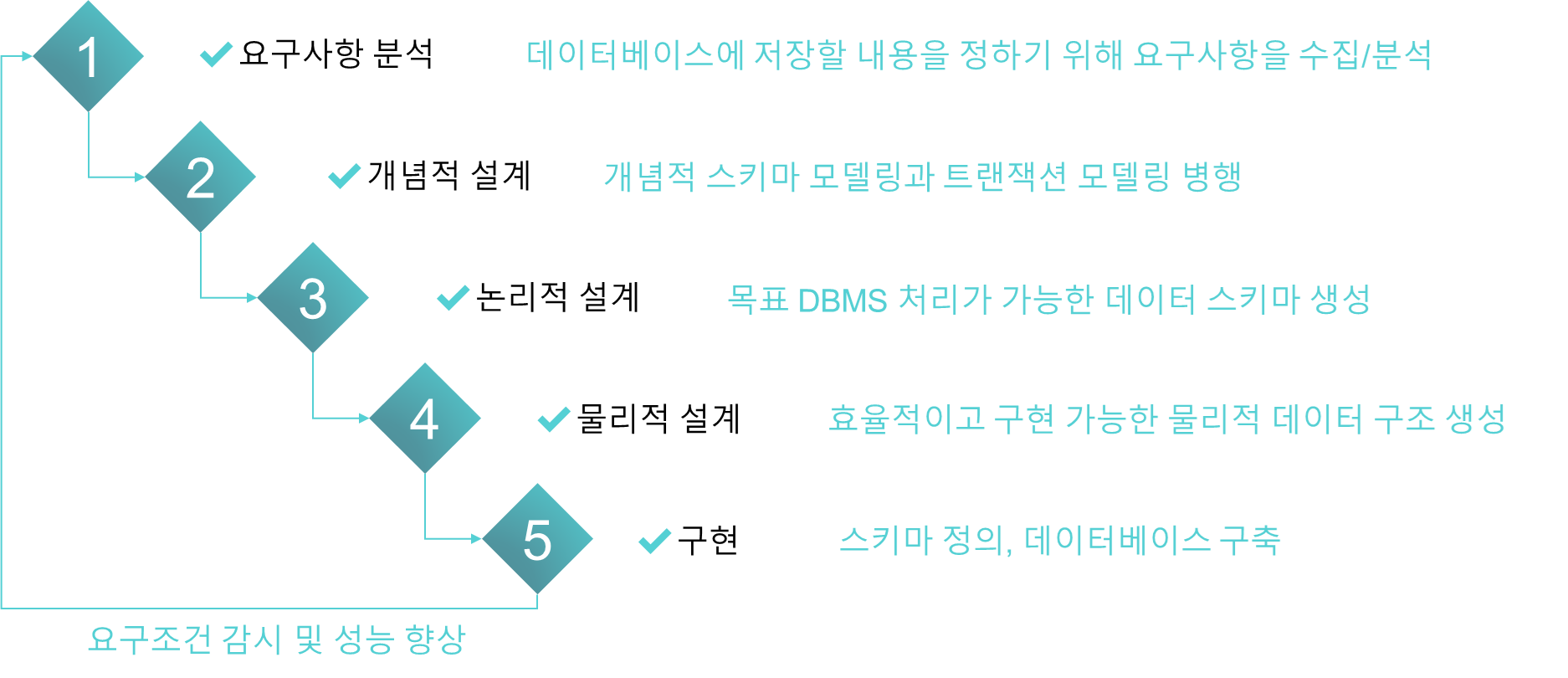
제가 야컴퓨터 공학 전공자가 아니라 완벽한 설계는 아니라는 점을 참고해 주시면 감사하겠습니다.
1) 요구사항 분석
(1) 데이터베이스의 사용자
- 교수님: 전체 데이터 수집 현황 및 분석 단계 파악
- 연구 간호사 선생님: 수집 및 저장 위치 파악, 환자 데이터 기입 및 관리
- 연구자: 데이터를 추출하여 분석에 사용
(2) 사용자를 고려한 목표
- 사용성이 편리한 데이터 베이스 구축
- 입력과 출력이 쉬운 데이터베이스 구축
- 연구실 인원 누구나, 언제, 어디서나 접근 가능한
(3) 데이터 베이스를 활용한 보고서 제작
- 한눈에 눈에 현재현재 분석단계를 찾아볼 수 있는 보고서 제작 ( => Dashboard 제작)
2) 개념적 설계 (ER 모델)
- 이 단계는 저장할 주제와, 각 테이블에 대한 어떤 속성들을 기입할 것인지 정하는 단계입니다.
(1) 엔티티(Entity) 정하기
저는 크게 대상자, 샘플, 보관, 서열, 프로젝트로 나누었습니다. 이들을 데이터베이스에서는 Entity 혹은 객체라고 합니다.
말 그대로 저장하고 싶은 대상을 말합니다.
- 대상자 (건강대조군 및 질환자)
- 샘플 (면봉, 분변, 배양 등)
- 보관 (냉장고 저장 위치, 혹은 타 연구실 이전)
- 서열 (FASTQ파일)
- 프로젝트 (전체 프로젝트의 수행도 관리)
(2) 속성(Attribute)을 정하기
속성은 각 엔티티에 들어갈 정보를 구성하는 작업입니다.
| Subjects (Health Controls & Patients)
SubjectID
DateOfBirth
VisitDate
Disease
Comorbidities
OnsetDate
Severity
Height
Weight
BMI
| Samples (Swab, Feces, Culture, etc.)
SampleID
SubjectID
CollectionSite
LesionOrNonLesion
Cohort
Collector
CollectionDate
StorageLocation
ProcessingStage
Project
SampleType
| Storage (Refrigerator Storage or Transfers)
SampleID
Refrigerator
Shelf
StorageBox
| Sequences (FASTQ Files)
SampleID
RunID
TargetRegion
SequencingPlatform
PassOrFail
StorageLocationServer
SampleStatus
TotalReads
GCContent(%)
AverageQuality
Q20(%)
Q30(%)
| Projects (Overall Project Management)
ProjectID
ProjectStage
SubjectsCollected
SamplesCollected
SubjectsAnalyzed
SamplesAnalyzed
SampleStorageLocation
AnalysisResultsLocation
3) 논리적 설계 (스키마 생성)
개념적 설계 이후 데이터의 관계를 알아보기 위해 ERD(Entity-Relationship Diagram)를 만들어 봅시다.
이 단계에서는 각 테이블의 기본키(Primary Key; PK)와 외래키 (Foreign Key; FK)를 정합니다.
- 기본키란 각 테이블의 레코드(Row)를 고유하게 인식하는 특정 열을 말합니다. 기본키는 중복값과 NULL값을 가질 수 없습니다.
- 외래키란 한 테이블이 다른 테이블의 기본키를 참조하는 열을 말합니다. 두 테이블 사이에 무결성 유지를 위해 사용됩니다.
이 단계에서 가장 중요한 것은 각 테이블 간의 관계를 정의하는 것 입니다.
여러 스키마 생성 도구가 있지만, ChatGPT를 활용하여 그려봅시다.
우리가 지정한 엔티티와 속성을 기반으로 mermaid.js코드를 만들어 달라고 한 다음에 "https://mermaid.live/"에 작성해 봅시다.
아래 ChatGPT의 답변을 통해 스키마를 그려봅시다.
erDiagram
Subjects {
string SubjectID PK "Primary Key"
date DateOfBirth
date VisitDate
string Disease
string Comorbidities
date OnsetDate
string Severity
float Height
float Weight
float BMI
}
Samples {
string SampleID PK "Primary Key"
string SubjectID FK "Foreign Key referencing Subjects"
string CollectionSite
enum LesionOrNonLesion "Lesion, Non-Lesion"
string Cohort
string Collector
date CollectionDate
string StorageLocation
string ProcessingStage
string Project
string SampleType
}
Storage {
string SampleID FK "Foreign Key referencing Samples"
string Refrigerator
string Shelf
string StorageBox
}
Sequences {
string SampleID FK "Foreign Key referencing Samples"
string RunID PK "Primary Key"
string TargetRegion
string SequencingPlatform
enum PassOrFail "Pass, Fail"
string StorageLocationServer
string SampleStatus
int TotalReads
float GCContent
float AverageQuality
float Q20
float Q30
}
Projects {
string ProjectID PK "Primary Key"
string ProjectStage
int SubjectsCollected
int SamplesCollected
int SubjectsAnalyzed
int SamplesAnalyzed
string SampleStorageLocation
string AnalysisResultsLocation
}
%% Relationships
Subjects ||--o{ Samples : "has"
Samples ||--o{ Storage : "stored in"
Samples ||--o{ Sequences : "has"
Projects ||--o{ Samples : "includes"
(참고: https://wikidocs.net/215336)

4) 물리적 설계
이제 실제 DBMS구축을 위해 각 속성의 형식을 정의하고 세부 속성을 정의한다.
(1) 데이터 형식 결정
- 숫자형: 정수형(INT, BIGINT) 또는 실수형(FLOAT, DECIMAL)으로 정의.
- 문자열형: 고정 길이(CHAR) 또는 가변 길이(VARCHAR) 문자열.
- 날짜/시간형: 날짜(DATE), 시간(TIME), 타임스탬프(DATETIME 또는 TIMESTAMP).
- 이진 데이터: 이미지나 파일 데이터를 저장하는 경우 BLOB 또는 VARBINARY.
- 열거형: 특정 값만 허용되는 경우 ENUM.
(2) 데이터 길이 설정
- 문자열 길이 제한: 예를 들어, 이름은 100자를 초과하지 않도록 VARCHAR(100)로 제한.
- 숫자 길이 제한: 정밀도와 소수 자릿수를 지정.
(3) NULL 허용 여부
- 속성이 필수인지(NOT NULL) 선택사항인지(NULL)를 결정.
(4) 인덱스 생성
(5) 뷰 설계
- 가상의 테이블로, 데이터베이스에서 원하는 데이터를 편하게 보기 위해 설계함
(참고: OpenAI. (2025). ChatGPT 4o [Large language model]. https://chat.openai.com)
(6) 물리적 저장 위치
- 연구실과 임상에서 접속 가능한 NAS 서버 사용하기 (병원망이라 외부 노출에 안전하다)
(7) O/I 및 DBMS 정하기
아래 후보 중에서 선정 예정이다.
a. csv로 파일 저장 후 DBeaver을 사용하여 MySQL 혹은 SQLite에 저장하여 관리
b. 마이크로소프트 사의 Access사용
c. Excel의 Power pivot사용
4. 활용방안
Dashboard 제작을 위해 R의 Shiny 혹은 Excel에서 완성할 것을 계획으로 두고 있습니다.
1) R와 데이터베이스 연동
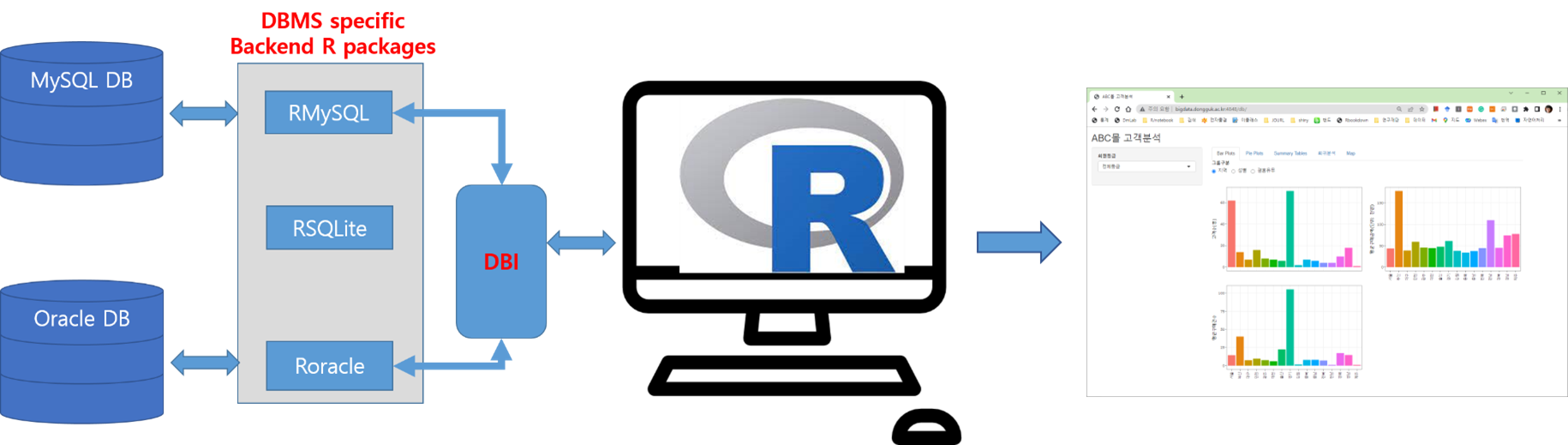
(출처: 김진성, 동국대학교, 통계데이터베이스 강의자료, 2022)
2) Excel에서 Dashboard제작
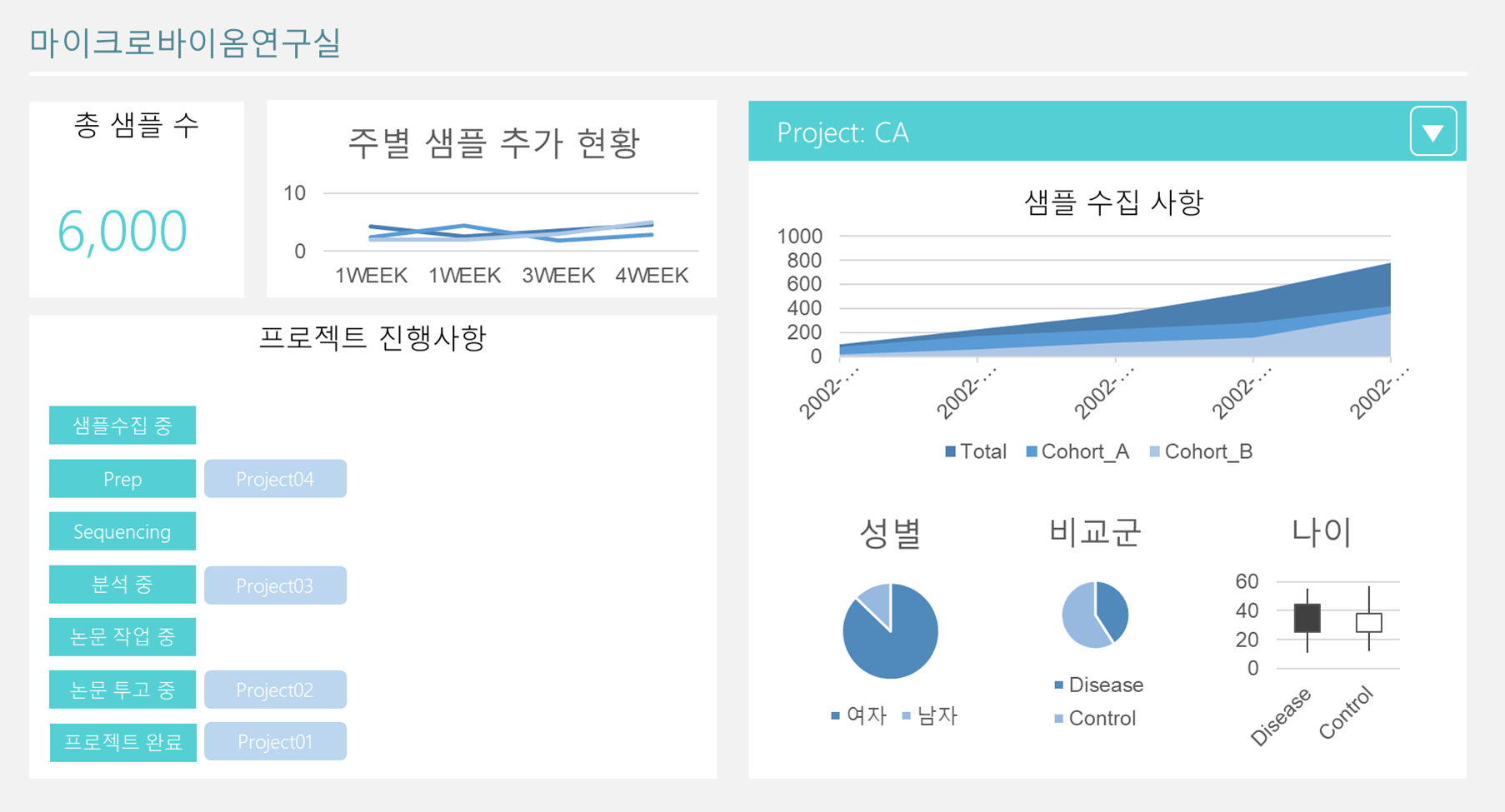
5. 향후 계획
일단 실제로 데이터베이스를 구축하면서 아래와 같은 글을 적어볼 생각입니다.
하지만 다 알고 적는거냐구요? 아뇨 이제 공부할 계획입니다 ㅎ...
- 데이터베이스를 제작해 보자 01: 데이터베이스 설계 ✔
- 데이터베이스를 제작해 보자 02: Excel power pivot을 사용한 데이터베이스 구현
- 데이터베이스를 제작해 보자 03: Excel에서 Dashboard를 제작하기
- 데이터베이스를 제작해 보자 04: Access를 사용한 전문적인 데이터베이스 관리
- 데이터베이스를 제작해 보자 05: MySQL을 사용한 전문적인 데이터베이스 관리
- 데이터베이스를 제작해 보자 06: R에서 MySQL데이터를 사용한 Shiny 대쉬보드 만들기
- 데이터베이스를 제작해 보자 完: 비전공자의 데이터베이스 제작 후기
참고
데이터베이스 설계 및 데이터분석 쿼리 작성 가이드 | 코딩추월차선
데이터베이스 설계를 위해 필요한 기본적인 지식과 ChatGPT를 활용한 데이터베이스 설계 방법과 테이블 생성 쿼리 작성 방법을 설명합니다.
www.developerfastlane.com
8. 데이터베이스
파이썬에는 SQLite [["데이터베이스"]]를 다루는 라이브러리가 내장돼 있어, 챗GPT의 고급 데이터 분석 기능에서 데이터베이스를 직접 생성하고 질의할 수 있다. - [전화…
wikidocs.net