
결론만 말하지만, unclutured와 unidentified는 reference에 등록이 되었으며, 분류기로 분류가 되었다.
그러나 이 생물이 실제로 배양 까다로워서 배양 결과가 없거나, Genus까지는 일치하는데 species level에서 판단이 안 되는 서열을 말한다.
unassigned = unclassified = NA는 같은 뜻이며, 분류기가 분류하지 못한 서열이라는 뜻이다.
우리는 대게 QIIME2에서 fit-classifier-sklearn를 사용하여 완성된 ASV와 가장 유사한 계통정보를 매칭시킨다.
예를 들어, 곰팡이 연구에서 많이 사용되는 UNITE database(for QIIME2)의 taxonomy정보를 보면, 데이터베이스 자체에서 unidentified, sp로 분류된 서열을 볼 수 있다.
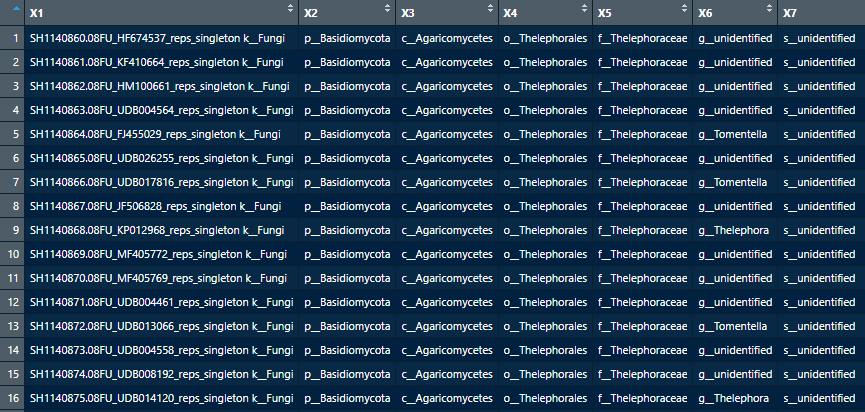
또한 세균 데이터베이스도 이와 마찬가지로 "s__unclutured"가 적힌 서열이 존재한다.
즉, uncultured와 unidentifed, sp모두 데이터베이스에 존재하는 서열에 매칭이 되었다는 이야기이다.
이 문구는 reference에 따라, 또는 같은 reference에서도 버전에 따라 다르다.
정리하자면, uncultured =/= unidentified = sp로 볼 수 있곘다.
하지만 unassigned, unclassified는 대게 아래와 같이 NA값이 나올 때, 이를 치환하는 문구이다. 즉, Species가 unassigned나 unclassified 혹은 NA값으로 논문에 표시되었다면, 분류기가 분류하지 못한 값이라는 뜻이다.
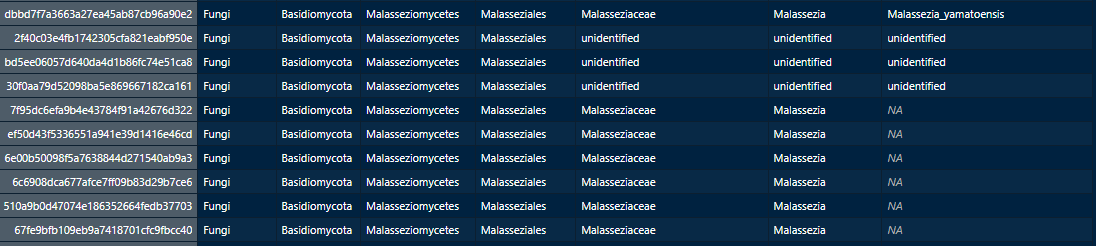
참고
결론만 말하지만, unclutured와 unidentified는 reference에 등록이 되었으며, 분류기로 분류가 되었다.
그러나 이 생물이 실제로 배양 까다로워서 배양 결과가 없거나, Genus까지는 일치하는데 species level에서 판단이 안 되는 서열을 말한다.
unassigned = unclassified = NA는 같은 뜻이며, 분류기가 분류하지 못한 서열이라는 뜻이다.
우리는 대게 QIIME2에서 fit-classifier-sklearn를 사용하여 완성된 ASV와 가장 유사한 계통정보를 매칭시킨다.
예를 들어, 곰팡이 연구에서 많이 사용되는 UNITE database(for QIIME2)의 taxonomy정보를 보면, 데이터베이스 자체에서 unidentified, sp로 분류된 서열을 볼 수 있다.
또한 세균 데이터베이스도 이와 마찬가지로 "s__unclutured"가 적힌 서열이 존재한다.
즉, uncultured와 unidentifed, sp모두 데이터베이스에 존재하는 서열에 매칭이 되었다는 이야기이다.
이 문구는 reference에 따라, 또는 같은 reference에서도 버전에 따라 다르다.
정리하자면, uncultured =/= unidentified = sp로 볼 수 있곘다.
하지만 unassigned, unclassified는 대게 아래와 같이 NA값이 나올 때, 이를 치환하는 문구이다. 즉, Species가 unassigned나 unclassified 혹은 NA값으로 논문에 표시되었다면, 분류기가 분류하지 못한 값이라는 뜻이다.
참고