

The Need for Averages
평균은 어디에나 있다. 스포츠에서, 우리는 팀이 승리할 것이라고 예상되는 수를 예측하려고 한다. 도박에서는, 우리는 블랙잭을 게임하면서 평균 실점을 예측하려고 한다. 비즈니스에서, 회사는 다음 분기의 평균 매출을 계산하려고 한다.
분자 생물학에서도 평균은 필요하다. 연구자는 평균적인 항생제 저항 병원균의 수를 예측하며, motif에 일치할 것이라고 예측되는 위치의 수를 추정하고, 인구 전체에 대한 대립 유전자 분포에 대한 평균을 연구한다.
이 문제에 대해서, 우리는 마지막 대립유전자 분포에 대해 논의해야 한다.
문제
1과 n사이의 정수값을 가지는 X 확률변수(random variable)에서, X의 기댓값(expected value )은 아래 그림과 같다.
기댓값은 샐 수 없이 많은 시행을 반복 했을때 확률변수에 대한 "장기적인" 평균을 제공한다.

예를 들면, 확률변수 X는 육면제 주사위의 숫자이다. 많은 시행동안 주사위를 굴렸을 때, 우리는 주사위에서 평균 3.5 ((1+2+3+4+5+6)/6 = 21/6 = 3.5)를 얻을 것이라고 예상한다..
기댓값의 공식은 아래와 같다.

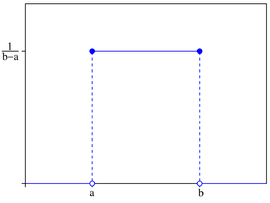
더 일반적으로, 각각의 확률변수가 동일한 확률 공간을 가진 변수를 균일확률변수(uniform random variable)라고 한다. 아래 그림처럼, 주사위의 예시에서 X가 가능한 최소값이 a, 최대 값이 b를 갖는 균일확률변수라면, 확률변수는 (a+b)/2의 값을 가진다.
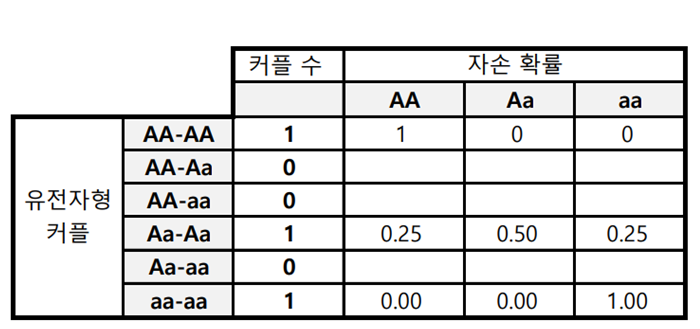
주어진 데이터 : 6개의 음수가 아닌 정수가 있다. 각 정수는 20,000을 넘지 않는다. 정수는 일치한다. 정수는 각 유전자 형을 쌍으로 가지는 짝을( ex. 3 = 3쌍 = 6명) 이루는 커플의 수와 일치한다. 주어진 6개의 수는 순서대로 나타낸다 아래의 유전자 형을 나타낸다.
- AA-AA : 1
- AA-Aa : 0
- AA-aa : 0
- Aa-Aa : 1
- Aa-aa : 0
- aa-aa : 1
반환값: 모든 커플이 정확히 두 명의 자손을 낳는 다는 가정 하에서 예상되는 다음 세대의 우세한 표현형을 가진 자손의 수를 반환하라
Sample Dataset
1 0 0 1 0 1
Sample Output
3.5
예제 데이터 풀이
각 유전자형에서 자손의 유전자형이 나올 확률을 아래와 같다

각 값을 표로 정리해보자
각 커플마다 자손을 두 명씩 낳는다고 했을 때, 기댓값은 확률 x 2 값을 가진다
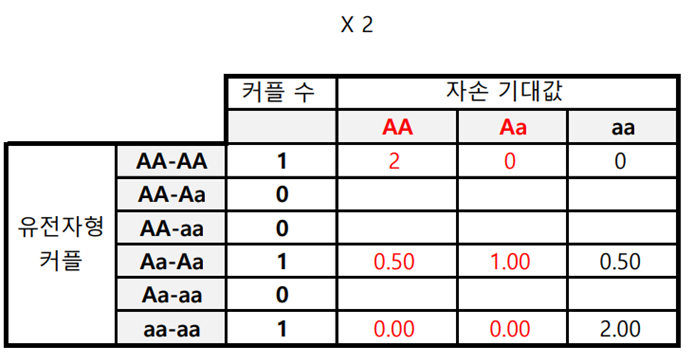
이때 우세한, 현성의 유전자 형을 가진 자손의 기댓값은 총 3.5이다.
풀이

단순히 우성인자를 가질 확률을 구하니까 단순히
- AAAA에서 우성 인자를 가질 확률 = 1
- AAAa에서 우성 인자를 가질 확률 = 1
- AAaa에서 우성 인자를 가질 확률 = 1
- AaAa에서 우성 인자를 가질 확률 = 0.75
- Aaaa에서 우성 인자를 가질 확률 =0.5
- aaaa에서 우성 인자를 가질 확률 = 0
로 계산하여서 단순 적용하였다.
with open('./test.txt', 'r') as f :
X = f.read().split()
AAAA, AAAa ,AAaa, AaAa, Aaaa, aaaa = map(int,X[0::])
Total = (AAAA*1) + (AAAa* 1) + (AAaa*1) + (AaAa*0.75) + (Aaaa* 0.5) + (aaaa*0)
print(Total*2)for 문으로 작업을 대체하고 각 확률에 대한 값을 자손수를 고려하여 *2한 상태로 보고
zip 파일로 각각 변수를 대조하려 계산하면 다음값과 같다.
with open('./test.txt', 'r') as f :
X = f.read().split()
sum([ a*int(b) for a,b in zip([2,2,2,1.5,1,0], X) ])by sharno with Python
zip()의 예제는 아래와 같다
(출처 : https://www.daleseo.com/python-zip/)
numbers = [1, 2, 3]
letters = ["A", "B", "C"]
for pair in zip(numbers, letters):
print(pair)
# (1, 'A')
# (2, 'B')
# (3, 'C')
R을 이용한 풀이
#!/usr/bin/Rscript
d.mul <- c(2, 2, 2, 1.5, 1, 0);
g1.counts <- as.numeric(unlist(strsplit("1 0 0 1 0 1"," ")));
sum(g1.counts * d.mul);